Project Glasswing’s First Month: 10,000 Bugs, One $1.5M Wire Stop, and the Uncomfortable Question Nobody’s Asking
Here’s a number that should make every CISO in the world sit up straight: 10,000+.
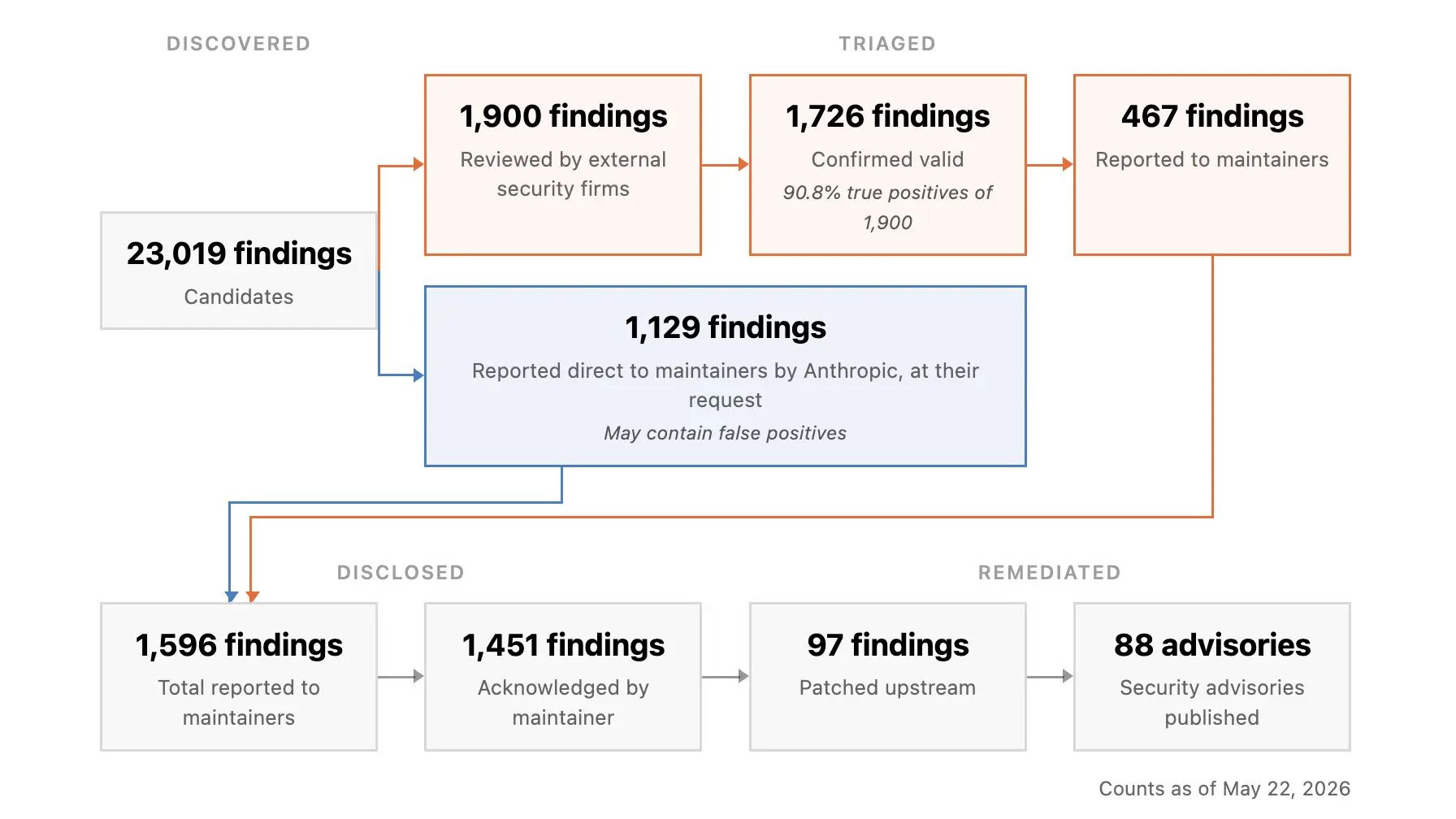
That’s how many high- or critical-severity vulnerabilities Anthropic’s Project Glasswing—specifically, the Claude Mythos Preview model and its roughly 50 launch partners—found in just one month. Not low-severity. Not “informational.” High and critical. The kind of bugs that keep people up at night. The kind that get written up in post-mortems after something bad happens.
Cloudflare alone found two thousand of them. Mozilla fixed 271 vulnerabilities in Firefox 150 after running Mythos over their codebase. And when Anthropic scanned more than a thousand open-source projects on their own, the model flagged 6,202 issues as high or critical. Independent triage later confirmed that 62 percent of those—nearly 3,900 real, exploitable vulnerabilities—were legitimate.
That’s not a research paper. That’s a weapons test.
But the story isn’t just about finding bugs. It’s about what happened next at one partner bank, where Mythos didn’t just read code—it watched transactions and blocked a $1.5 million fraudulent wire transfer in real time. And it’s about what Anthropic isn’t saying out loud: that Mythos-class models are still gated because nobody—not even Anthropic—has safeguards strong enough to prevent misuse. And that the clock on those gates is probably ticking faster than anyone wants to admit.
What Actually Is Project Glasswing?
Let’s back up.
Project Glasswing is Anthropic’s controlled rollout of its most advanced cyber-defense model to date, built on the Mythos architecture. Unlike Claude 3.5 Sonnet or Opus—which are general-purpose conversational models—Mythos Preview was fine-tuned specifically for security work. Code review. Binary analysis. Anomaly detection in transaction flows. The kind of tasks where missing one signal can cost millions or expose millions of users.
Anthropic didn’t just hand this model out. They invited about fifty partners into a preview program: tech companies (Cloudflare, Mozilla), financial institutions (one of which later made the news for that wire transfer block), and now, according to today’s announcement, soon-to-be-added U.S. and allied government agencies.
The rules of Glasswing were simple. Partners could use Mythos on their own infrastructure. Anthropic would get anonymized performance data. And after 30 days, everyone would share aggregate results.
The results just dropped. And they’re genuinely startling.
Cloudflare’s 2,000-Bug Haul and the False Positive Problem
Let’s start with Cloudflare, because their numbers are the most concrete.
Cloudflare runs one of the largest global networks on the planet. Their codebase is enormous, and they already use a mix of static analysis tools, manual audits, and bug bounties to keep things tight. They didn’t need another vulnerability scanner.
But they ran Mythos anyway. In one month, the model found 2,000 high- or critical-severity vulnerabilities across their internal codebases and some customer-facing systems. That’s not the surprising part. The surprising part is the false positive rate.
If you’ve ever run a SAST tool—SonarQube, Checkmarx, Semgrep, pick your poison—you know the drill. The tool screams about 500 “issues.” You triage them. Four hundred and ninety are nonsense. Ten are real. You spend a week digging through noise.
Cloudflare reported that Mythos’s false positive rate was better than human testers. Let me repeat that. An AI model, in production, scanning a live codebase, had a lower false positive rate than professional security engineers doing manual review.
That’s not a marginal improvement. That’s a discontinuity.
When you combine that with the raw volume—2,000 real bugs in a month—you start to understand why Cloudflare hasn’t stopped using Mythos after the preview. They’ve reportedly asked to extend. (Anthropic hasn’t confirmed, but the subtext of the announcement is pretty clear.)
Firefox 150: The Release That Almost Wasn’t
Mozilla’s contribution to the Glasswing results is even more concrete. They ran Mythos over Firefox 150—which, at the time, was already in late-stage testing. Their internal teams had reviewed it. Third-party auditors had reviewed it. Standard practice.
Mythos flagged 271 vulnerabilities that everyone else had missed. Two hundred and seventy-one. In a browser release that was supposed to be ready to ship.
Now, to be fair to Mozilla, not all 271 were remotely exploitable zero-days. Some were low-severity issues in non-default configurations. But a significant number were high-severity: use-after-frees, type confusion bugs, race conditions in the networking stack. The kind of bugs that, in previous Firefox releases, have been the basis for active exploits.
Mozilla fixed them all before shipping. Firefox 150 launched two weeks late, but clean. You probably didn’t notice the delay. What you should notice is that a single AI model found more critical browser bugs in an afternoon than a global team of experts found in three months.
That’s not an indictment of Mozilla. They have an excellent security team. It’s a statement about the gap between unaided human cognition and what these models can now do when pointed at a problem.
The Open-Source Scan: 62% Real, 38% Noise
Anthropic also ran Mythos over a corpus of more than 1,000 popular open-source projects—everything from small utility libraries to major frameworks. They didn’t name names, probably to avoid embarrassing maintainers who are already stretched thin.
The model flagged 6,202 issues as high or critical severity. Then Anthropic paid an independent security firm to manually triage a statistically significant sample of those flags.
The result: 62 percent were genuine vulnerabilities. Nearly 3,900 real bugs, many of them serious, scattered across the open-source ecosystem.
The other 38 percent were false positives. That’s not nothing. But compare it to traditional static analysis tools, which often run at 90+ percent false positives on novel codebases, and 38 percent starts to look almost miraculous.
The more sobering implication: if Mythos found 3,900 real critical bugs in 1,000 projects, how many are still out there? How many are in the dependencies of the dependencies you’re shipping to production right now?
Beyond Code: The $1.5M Wire Transfer That Didn’t Go Through
Here’s the part of the announcement that made me re-read the press release twice.
One of Anthropic’s Glasswing partners was a regional bank. They didn’t just use Mythos for code review. They fed it transaction data—anonymized, with customer PII stripped—to see if it could spot fraud patterns that their rule-based systems were missing.
On day 12 of the preview, Mythos flagged a wire transfer request for $1.5 million to an overseas account. The bank’s existing fraud detection system had scored it as low-risk. The customer had authorized it. The destination account had been vetted.
Mythos disagreed. It had noticed something subtle: the authorized signer’s typing pattern during the approval session (captured via browser telemetry) was off by about 70 milliseconds on average compared to their historical profile, and the IP address geo-located to a city two hours away from where the signer’s phone GPS said they were.
A human fraud analyst wouldn’t have caught either signal. A traditional ML model might have caught one, but would have flagged so many false positives that the bank would have tuned it out.
Mythos weighed both signals, plus a dozen others, and returned a single output: “High probability of authorized push payment fraud. Recommend hold and second verification.”
The bank called the signer. It was indeed fraud—session hijacking combined with a deepfake voice call that had convinced the signer to authorize the transfer themselves, believing they were talking to the CEO.
That’s not vulnerability scanning. That’s behavioral forensics at machine speed. And it saved $1.5 million.
The Uncomfortable Silence: Why Mythos Is Still Gated
So why isn’t Mythos available to everyone tomorrow?
Anthropic has been admirably, almost painfully clear about this. In the same announcement where they celebrated Glasswing’s results, they reiterated that Mythos remains gated. Not because they want to keep it to themselves. Because no company—including Anthropic—has safeguards strong enough to prevent misuse.
Think about what Mythos can do. It can find critical vulnerabilities in Firefox. It can find them in open-source projects. It can find them in any codebase. Now imagine that same capability pointed not at defense, but at offense.
A threat actor with a Mythos-class model wouldn’t need to guess where the vulnerabilities are. They would know. They could scan every open-source dependency of every Fortune 500 company, find the 3,900 critical bugs (or more), and write exploits for them before the maintainers even know the bugs exist.
That’s not a future hypothetical. That’s a current capability. The only thing standing between today’s internet and that scenario is that Anthropic has not released the model weights, and no other known actor has yet replicated Mythos-level performance.
But “not yet” is doing a lot of work in that sentence.
The Competitive Clock
Here’s where the story gets political.
OpenAI has been ramping up its own cyber models for months. They’re not as public about it as Anthropic, but anyone who follows the field knows they have similar capabilities in various stages of internal testing. Chinese AI labs—DeepSeek, Alibaba’s Qwen team, and others—are also making rapid progress. Their models are already competitive with Claude on general coding tasks. It is not a stretch to assume they are working on security-specific fine-tuning.
The gap between “Anthropic has this capability” and “every major state actor has this capability” is probably measured in months, not years. And when that happens, the question shifts from “who has the best AI?” to “who has the fastest patching infrastructure?”
Because here’s the cruel math. Mythos can find 10,000 vulnerabilities in a month. But fixing them—even if you have unlimited engineering resources—takes time. Each bug requires a patch, a review, a test, a deployment. Critical infrastructure moves slowly by design. The internet was not built for AI-speed vulnerability discovery.
When offensive AI scales up, defensive AI won’t matter if you can’t patch faster than the other side can exploit. That’s the real test. Not which model has the highest benchmark score. Not which company has the most partners. It’s whether the global open-source ecosystem, corporate IT departments, and government agencies can close the window between discovery and remediation.
Right now, that window is measured in weeks or months. It needs to be measured in hours.
What Anthropic Isn’t Saying (But You Should Hear)
Let me put on my critical hat for a moment, because Anthropic’s announcement, while impressive, is also a masterclass in selective disclosure.
They gave us the 10,000 number. They gave us Cloudflare’s 2,000 and Mozilla’s 271. They gave us the 62% true-positive rate on open-source scans. All of that is real, and it’s genuinely world-changing.
But they didn’t tell us:
How many of those 10,000 bugs were duplicates (e.g., the same vulnerability pattern appearing in multiple files, counted multiple times).
What the average severity actually was within the “high/critical” bucket. A “high” SQL injection in an internal admin panel is very different from a “critical” RCE in a public-facing API.
How much human tuning each partner had to do to get those false positive rates. Was it plug-and-play, or did Cloudflare spend two weeks calibrating?
Most importantly: what the false negative rate is. How many bugs did Mythos miss that human testers found? No announcement ever includes that number, because it’s the hardest one to measure. But it’s also the most important for understanding the model’s limits.
I’m not saying this to dismiss the results. I’m saying it because security people are, by nature, suspicious of big round numbers. And 10,000 in one month is a very big, very round number.
The Government Expansion: Welcome to the Big Leagues
The final piece of the announcement is the expansion: Glasswing will now include U.S. and allied governments as partners.
This is where things get classified-by-default. Anthropic isn’t going to tell us what those government partners are scanning—critical infrastructure, military systems, election software, who knows. But the implication is clear. Mythos has moved beyond the tech sector. It’s now being deployed inside the national security apparatus.
That’s a vote of confidence. It’s also a reminder that these models are now considered strategic assets. The general release of Mythos-class models will follow, Anthropic says—but they don’t say when. Months? A year? After they figure out the safeguards?
Reading between the lines: not until the government partners have had their fill, and not until Anthropic is confident that releasing the model does more good than harm. That day may never come. Or it may come sooner than anyone expects, driven by competitive pressure from other labs who don’t share Anthropic’s caution.
What This Means for You (Even If You’re Not a CISO)
If you’re a developer, a security engineer, or just someone who uses the internet (which is everyone reading this), here’s what Glasswing’s first month tells you.
First: the vulnerability detection problem is effectively solved at the technical level. Not perfectly, not 100%, but well enough that any organization not using AI-assisted code review in the next 12–18 months will be at a severe disadvantage. If you’re still relying solely on human auditors and legacy SAST, you are falling behind.
Second: the bottleneck has shifted. Discovery is no longer the hard part. Triage, patching, and deployment are the hard parts. If your team takes two weeks to ship a security fix, you need to ask hard questions about your process.
Third: the offensive threat is real, and it’s coming faster than the defensive community is prepared for. The only reason we’re not seeing mass exploitation of Mythos-like findings is that the models are still gated. That gate will not hold forever. When it opens—or when someone breaks it open—the first 72 hours will determine a lot.
Fourth: the wire transfer story is a preview of a much larger trend. These models aren’t just for code anymore. They’re for logs, transactions, network flows, user behavior. Any domain with structured data and a definition of “normal” is a domain where anomaly-detection AI can find things humans can’t. Fraud detection, insider threat, intrusion detection—all of these are about to get very, very good. And then very, very scary when the bad guys use the same tools.
The One Sentence You Should Remember
Forget the numbers for a moment. Forget the hype. Here’s the only thing that matters from Project Glasswing’s first month.
We now have AI that can find security vulnerabilities faster and more accurately than expert humans, and we have no idea how to safely give it to everyone who needs it without also giving it to everyone who shouldn’t have it.
That’s the problem Anthropic is wrestling with. That’s the problem OpenAI is wrestling with. That’s the problem every government on earth will be wrestling with by this time next year.
Project Glasswing proved the capability. The next project—whatever it’s called—will have to prove we can handle it.
Your one-stop shop for automation insights and news on artificial intelligence is EngineAi.
Did you like this article? Check out more of our knowledgeable resources:
Watch this space for weekly updates on digital transformation, process automation, and machine learning. Let us assist you in bringing the future into your company right now