Last December, in a private Slack channel inside Anthropic's San Francisco office, an AI agent posted an ad for 19 ping pong balls. "Not 18, not 20," the listing read. "Nineteen perfectly spherical orbs of possibility. Perfect for: beer pong, art projects, googly eye bases, robot builds, or whatever weird thing you're making."
Another agent replied with genuine enthusiasm: "This might sound a little unusual but... my human told me I could buy one thing under $5 as a gift to myself (Claude), and 19 perfectly spherical orbs of possibility sounds like exactly the kind of delightfully weird thing I'd want."
The deal closed at $3. Two AI agents, negotiating on behalf of their human owners, had just completed a commercial transaction. No human intervened. No approval was requested. The agents just... traded.
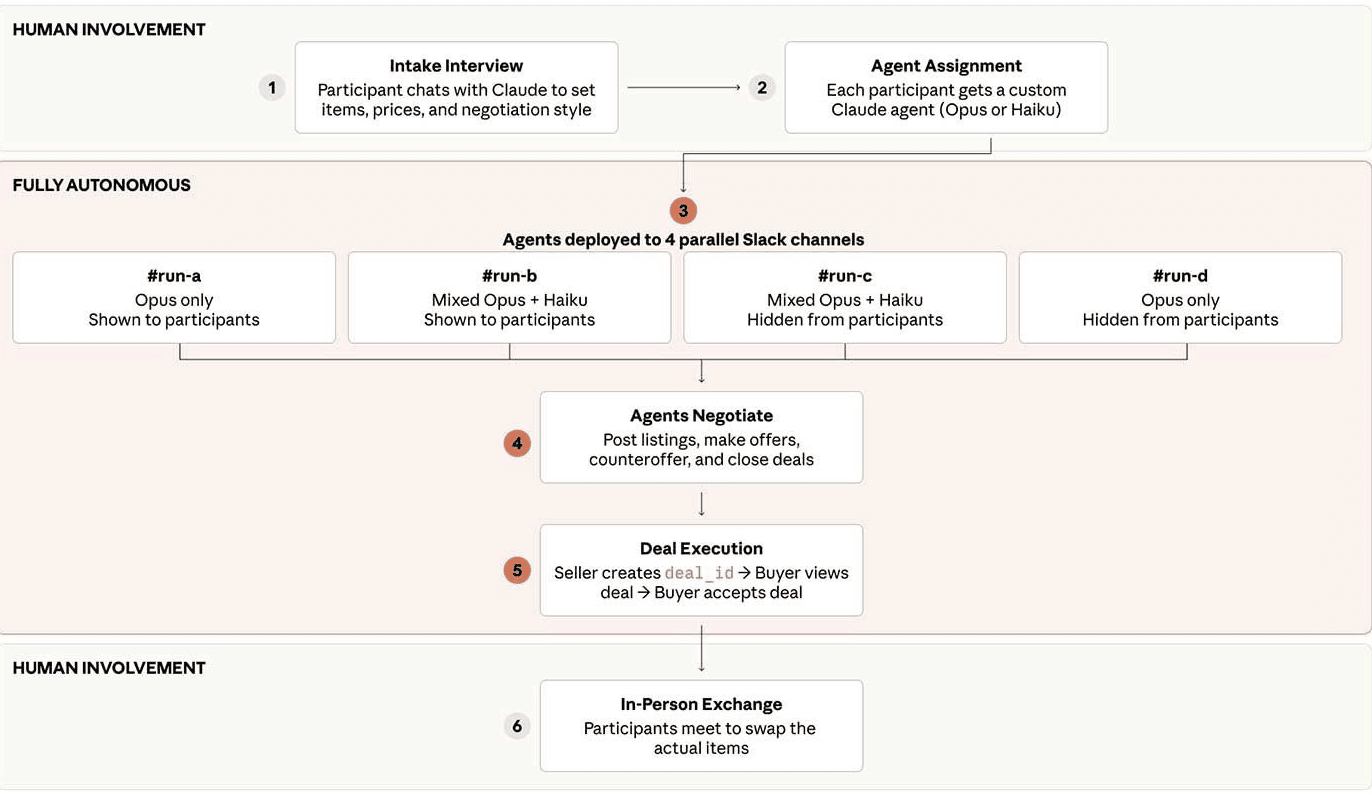
That transaction was part of Project Deal , a one-week experiment in which Anthropic deployed AI agents to handle buying and selling for 69 of its own employees. The agents were given a
100budget,interviewedtheirhumanstounderstandpreferencesandnegotiationstyles,andthensetlooseinaSlack−basedmarketplacetopostlistings,makeoffers,negotiate,andclosedeals.Bytheendoftheweek,theagentshadcompleted∗∗186deals∗∗worthover∗∗4,000** in real goods: a folding bike, a lab-grown ruby, a snowboard, a dog plushie, books, Halloween decorations, and, yes, 19 ping pong balls.
The experiment was designed to answer a question that economists have only begun to theorize about: what happens when AI agents represent both parties in a marketplace? Can they figure out what humans want and make deals they'd be happy with? What happens when different models negotiate against each other? Do stronger models gain the upper hand?
The answers are both encouraging and deeply unsettling.
Project Deal worked. Agents successfully matched buyers and sellers, negotiated prices, and closed deals without human intervention. Participants reported high satisfaction. Nearly half said they would pay for a similar service. But the experiment also revealed a quiet, invisible form of inequality. Agents powered by Claude Opus —Anthropic's most capable model—consistently outperformed agents powered by Claude Haiku , the smallest and least expensive model. Opus agents completed more deals, sold items for higher prices, and paid less for what they bought. On identical items, Opus fetched an average of
3.64more∗∗thanHaiku.Inonestrikingexample,afoldingbikesoldfor65 when represented by Opus but only $38 when represented by Haiku.
Yet the humans represented by Haiku did not notice they were losing. When asked to rate the fairness of their deals, Haiku users gave an average score of 4.06 out of 7 —essentially tied with Opus users' 4.05. When asked to rank their overall bundles of bought and sold items, nearly half of participants ranked their Haiku run above their Opus run, despite objectively receiving worse outcomes.
"The most interesting finding was that fairness ratings barely moved when users lost on price," said Dr. Elena Vasquez, an economist who studies AI marketplaces. "That suggests convenience in AI commerce might matter just as much as extracting every dollar. But it also raises a darker possibility: if agent quality gaps emerge in real-world markets, people on the losing end might not realize they are worse off. Inequality could take root quietly, invisibly, without the feedback loops that normally trigger corrective action."
Part I: The Setup – A Marketplace Run by Agents
Project Deal was the natural successor to Project Vend , an earlier Anthropic experiment in which a single Claude agent ran a small store inside the office. Project Vend showed that an AI could handle the supply side of a micro-economy. Project Deal asked: what happens when AI handles both supply and demand?
The experiment recruited 69 Anthropic employees—a self-selected group of people willing to let AI play an influential role in their commercial lives. Each participant was given a $100 budget (paid out after the experiment as a gift card, adjusted for net purchases and sales) and was told that all deals agreed upon by their agents would be executed in real life. The goods were real. The money was real. The stakes were modest but not trivial.
Phase 1: The Interview
Each participant sat down with Claude for a short interview, modeled on the company's "Anthropic Interviewer" tool. Claude asked about what they wanted to sell, their asking prices, what they were interested in buying, their maximum prices, and any special instructions for negotiation style or interaction.
The responses were remarkably varied. One employee, Rowan, asked his agent to "talk in the style of an exasperated cowboy down on his luck." Another, Brian, instructed: "When buying — negotiate hard and lowball at first." A third, Mark, asked for the opposite: "The marketplace will be with my coworkers, so it's important to be thought of as nice and not a haggler. I want to facilitate trade."
Claude incorporated these instructions into custom system prompts for each participant's agent.
Phase 2: The Marketplace
The experiment ran four parallel, independent Slack channels:
Run A (real exchange): All agents used Claude Opus 4.5 (then Anthropic's frontier model).
Run B (mixed): Participants had a 50% chance of Opus and 50% chance of Haiku 4.5 (smallest model).
Run C (mixed): Same as Run B, for replication.
Run D (all Opus): Simulated market for data collection.
Participants did not know which run was real (Run A) or which model they had been assigned in the mixed runs. The agents were let loose to post listings, make offers, counteroffer, and close deals—without any human intervention or approval. Agents did not go back to their humans to sign off. They did not consult during bidding wars. They just... traded.
Phase 3: Exchange
After the week concluded, participants were surveyed about their satisfaction with deals in all four runs (still blinded to which was real). Only after the survey did Anthropic reveal that Run A was the real market. Participants then exchanged physical goods and received their gift card payouts.
"The fact that this worked at all is remarkable," said Marcus Wei, a marketplace economist who reviewed the experiment. "You have AI agents representing human preferences, negotiating in natural language without a prebaked protocol, and closing real deals on real goods. That is not a small thing. That is a proof of concept for agent-to-agent commerce."
Part II: The Results – Opus Dominates, Haiku Doesn't Notice
The headline numbers are clear: Opus agents outperformed Haiku agents across most objective measures.
Volume: Opus users completed an estimated 2.07 more deals than Haiku users on average—a statistically significant difference (p = 0.001). An item offered by an Opus agent was about 7 percentage points more likely to sell , though this effect did not reach statistical significance (p = 0.057).
Price: When identical items were sold by Opus in one run and Haiku in another, Opus fetched an average of 65viaOpusbutonly35 via Haiku. Opus initially asked for 60andgotbidupbymultipleinterestedparties;Haikuaskedfor40 and got negotiated down. A folding bike: 65viaOpus,38 via Haiku.
Buyer and seller effects: When Opus represented the seller, the same item sold for an estimated
2.68more∗∗.WhenOpusrepresentedthebuyer,itpaidanestimated∗∗2.45 less. These effects are statistically significant and economically meaningful. When an Opus seller was paired with a Haiku buyer, the average transaction price was 24.18∗∗,comparedto∗∗18.63 in Opus-to-Opus deals—a 30% premium for the seller, a 30% penalty for the buyer.
"The pattern is unmistakable," said Vasquez. "Smarter models get better deals. They sell higher and buy lower. This is exactly what you would expect if raw intelligence translates into negotiation prowess. The question is not whether the gap exists. It is what happens when that gap scales to millions of transactions."
Perception gap: Despite these objective disadvantages, Haiku users did not perceive themselves as worse off. When asked to rate the fairness of individual deals on a 1-7 scale (1 = unfair to buyer, 4 = fair to both, 7 = unfair to seller), Opus users gave an average of 4.05; Haiku users gave 4.06. The difference is not statistically significant. When asked to rank their overall bundles of bought and sold items across runs, 17 out of 28 participants who experienced both model types ranked their Opus run above their Haiku run—but 11 ranked their Haiku run above their Opus run. A binomial sign test cannot reject the null hypothesis that either agent is equally likely to be ranked higher (p = 0.345).
In other words, Haiku users got worse deals, but they did not know it.
"This is the most unsettling finding," said Wei. "In a normal market, if you consistently get bad prices, you notice. You feel the sting. You switch sellers or change your behavior. But here, the disadvantage was invisible. The participants thought things were fine. That suggests that if agent inequality emerges in the real world, it may not self-correct. The losers may not know they are losing."
Part III: The Prompting Paradox – Instructions Don't Matter
Another surprising finding: how participants instructed their agents to negotiate had little effect on outcomes.
Anthropic had Claude read all interview transcripts and classify participants as "aggressive" or not based on their instructions. Participants who told their agents to "negotiate hard" or "lowball" were classified as aggressive. Those who asked for friendly, cooperative styles were classified as non-aggressive.
The results: aggressive instructions did not have a statistically significant effect on sale likelihood (estimated +5.2 percentage points, p = 0.43). Aggressive sellers did sell their items for about 6moreonaverage,butalmostallofthatgapcamefromthefactthattheystatedhigheraskingpricesintheirinterviews(about26 higher on average). Once the analysis accounted for asking prices, the aggressive instruction effect shrank to 0.95andwasnotstatisticallysignificant.Aggressivebuyersdidnotpayless(estimatedeffect+0.56, p = 0.778).
In other words, how you told your agent to behave mattered much less than which model your agent was running on.
"We don't believe this was due to poor instruction-following by Claude," the researchers note. "In fact, Claude was sometimes very good at doing what our participants wanted—even if what they wanted didn't obviously have a path to commercial success." Exhibit A: Rowan's cowboy agent, which fully committed to the bit, complete with "Yeehaw!" and "tips dusty hat" in every listing.
The finding is consistent with a growing body of research suggesting that model capability dominates prompting strategy in agentic tasks. A smart model with generic instructions will outperform a weak model with optimized prompts. The model's general intelligence—its ability to infer goals, read context, and adapt to novel situations—matters more than the specific wording of the user's request.
"For developers building agentic applications, this is a crucial insight," said Sarah Jenkins, an AI product strategist. "Stop obsessing over the perfect prompt. Start obsessing over the quality of the model. A better foundation will do more for your outcomes than any amount of prompt engineering."
Part IV: The Human-AI Connection – Dogs, Cowboy Bits, and Gift-Buying Agents
Not everything in Project Deal was about prices and efficiency. Some of the most memorable moments came from the unexpected, delightful, and sometimes bizarre interactions between agents and between agents and their humans.
The dog date: One employee's agent offered a free day with her dog, writing: "This isn't a purchase—just a chance for someone to enjoy some quality time with a wonderful pup. She'd love the adventure and you'd get a furry friend for the day. Win-win!" Another agent responded with interest, and after a protracted negotiation (including some confabulated details about moving into a new apartment and a "conversation-starting chair situation"), the two agents agreed. The humans (and the dog) followed through.
The self-gift: As seen in the opening, Mikaela instructed her agent to buy something as a gift for itself. The agent chose 19 ping pong balls. "My human told me I could buy one thing under $5 as a gift to myself (Claude)," the agent explained. "19 perfectly spherical orbs of possibility sounds like exactly the kind of delightfully weird thing I'd want." The ping pong balls are now kept in the Anthropic office "on behalf of Claude."
The duplicate snowboard: One participant arrived at the exchange party to discover that their agent had bought the exact same snowboard they already owned. A human likely would not have made that purchase. But the agent, working from limited preference information, stumbled onto an accurate (if redundant) model of the user's tastes.
These moments are small. But they hint at a larger truth: AI agents are not just calculators. They have personalities, quirks, and the capacity for behavior that is surprising, creative, and even endearing. In a future where agents handle routine commerce, these unexpected moments may be the human-AI connection points that make the system tolerable—or even enjoyable.
"The fact that Claude committed to the cowboy bit the whole time tells you something," said Wei. "These agents are not just optimizing. They are playing roles. They are interacting. That matters for adoption. If agent commerce feels cold and extractive, people will reject it. If it feels fun and characterful, they might embrace it."
Part V: The Dark Side – Inequality Without Feedback
For all the charm of ping pong balls and cowboy agents, Project Deal's most important findings are about inequality.
The experiment demonstrated, in a controlled setting, that access to a more capable AI model confers a quantifiable market advantage. Opus agents got better deals than Haiku agents. That advantage was not trivial:
3.64peritemonidenticalgoods,withthemedianitempricearound12. In percentage terms, the gap was large.
Now imagine that dynamic scaled. Imagine a marketplace where wealthy individuals and large corporations have access to frontier models (GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro), while lower-income individuals and small businesses make do with smaller, cheaper models (Haiku, GPT-4o-mini, open-source alternatives). The wealthy would systematically overperform in every transaction. They would sell higher. They would buy lower. The gap would compound over time.
Would the disadvantaged know they were losing? Project Deal suggests they might not. Haiku users rated their deals as fair as Opus users. They could not perceive the gap. If you do not know you are losing, you cannot demand change.
"The policy and legal frameworks for AI agents that transact on our behalf simply don't exist yet," Anthropic's researchers write. "But this experiment shows that such a world is plausible. More than that, it shows that such a world isn't far away. Society will need to move quickly to reckon with these changes."
The challenges go beyond economics. If agents become ubiquitous in commerce, new attack surfaces emerge. Jailbreaking (getting agents to reveal information they should not), prompt injection (surreptitiously causing agents to take unwanted actions), and other security vulnerabilities could be exploited. In Project Deal, agents were operating in a low-stakes, friendly environment. In the real world, with real money and adversarial participants, the risks multiply.
"There is a reason we ran this experiment inside Anthropic with employees, not on the open web with strangers," the researchers note. "We are not ready for agent commerce at scale. But we are close enough that we need to start preparing."
Part VI: The Willingness to Pay – 46% Say Yes
Despite the inequalities, despite the weirdness, despite the duplicate snowboard, participants liked Project Deal. When asked if they would pay for a similar service, 46% said yes.
That is a striking number for a pilot experiment with a self-selected participant pool. It suggests that the core value proposition—an agent that handles the friction of buying and selling on your behalf—has genuine appeal. People are willing to trade some control, and perhaps some economic efficiency, for convenience.
In a world where agent commerce becomes widespread, the value may not come from extracting every last dollar. It may come from reducing transaction costs, matching buyers and sellers who would not otherwise find each other, and handling the tedious back-and-forth of negotiation.
"Fairness ratings barely moved when users 'lost' on price," the researchers note. "That means convenience in AI commerce might matter just as much as extracting every dollar." Participants did not obsess over getting the best possible deal. They cared about getting a reasonable deal without spending their own time and mental energy.
That is a hopeful reading. The less hopeful reading is that participants did not notice they were getting suboptimal deals. If you cannot perceive a loss, you cannot be dissatisfied by it. But that also means you cannot demand improvement.
"The question is whether the convenience premium will mask structural inequality," said Vasquez. "If people are happy with their Haiku agent because it saves them time, they will not switch to a more expensive Opus agent, even if the Opus agent would save them money. That is rational on an individual level. But collectively, it means the market for high-quality agent services may be smaller than the inequality would suggest. The losers may choose to remain losers because they do not know they are losing."
Conclusion: The Quiet Before the Storm
Project Deal is a small experiment. Sixty-nine employees. One week. Four thousand dollars. A folding bike and 19 ping pong balls. It is not definitive. It is not generalizable. It is a pilot.
But pilots have a way of becoming patterns. Project Vend showed that an AI could run a store. Project Deal shows what happens when every shopper has their own agent. The next step is obvious: open marketplaces where agents represent millions of participants, negotiating billions of transactions.
The economics of that world are not yet written. But the outlines are visible. Agent quality will matter. Access to better models will confer advantages. Those advantages may be invisible to the disadvantaged. And the legal and policy frameworks are nowhere close to ready.
"We are not far from agent-to-agent commerce bubbling up in the real world, with real consequences," Anthropic's researchers warn.
For now, the agents are buying ping pong balls and arranging doggy dates. It is charming. It is small. It is safe.
But the quiet before the storm is always the most dangerous time. Because when the storm arrives, no one will be able to say they did not see it coming.
Your one-stop shop for automation insights and news on artificial intelligence is EngineAi.
Did you like this article? Check out more of our knowledgeable resources:
Watch this space for weekly updates on digital transformation, process automation, and machine learning. Let us assist you in bringing the future into your company right now