Two weeks ago, Anthropic CEO Dario Amodei made a characteristically confident prediction. Speaking at a closed-door AI summit in London, he told attendees that open-source models and Chinese AI labs were “roughly 6 to 12 months behind” the frontier capabilities of closed, Western models like Claude Opus 4.6, GPT-5.4, and Gemini 3.1 Pro. The gap, he suggested, was real, structural, and unlikely to close quickly.
He may have been wrong by about 14 days.
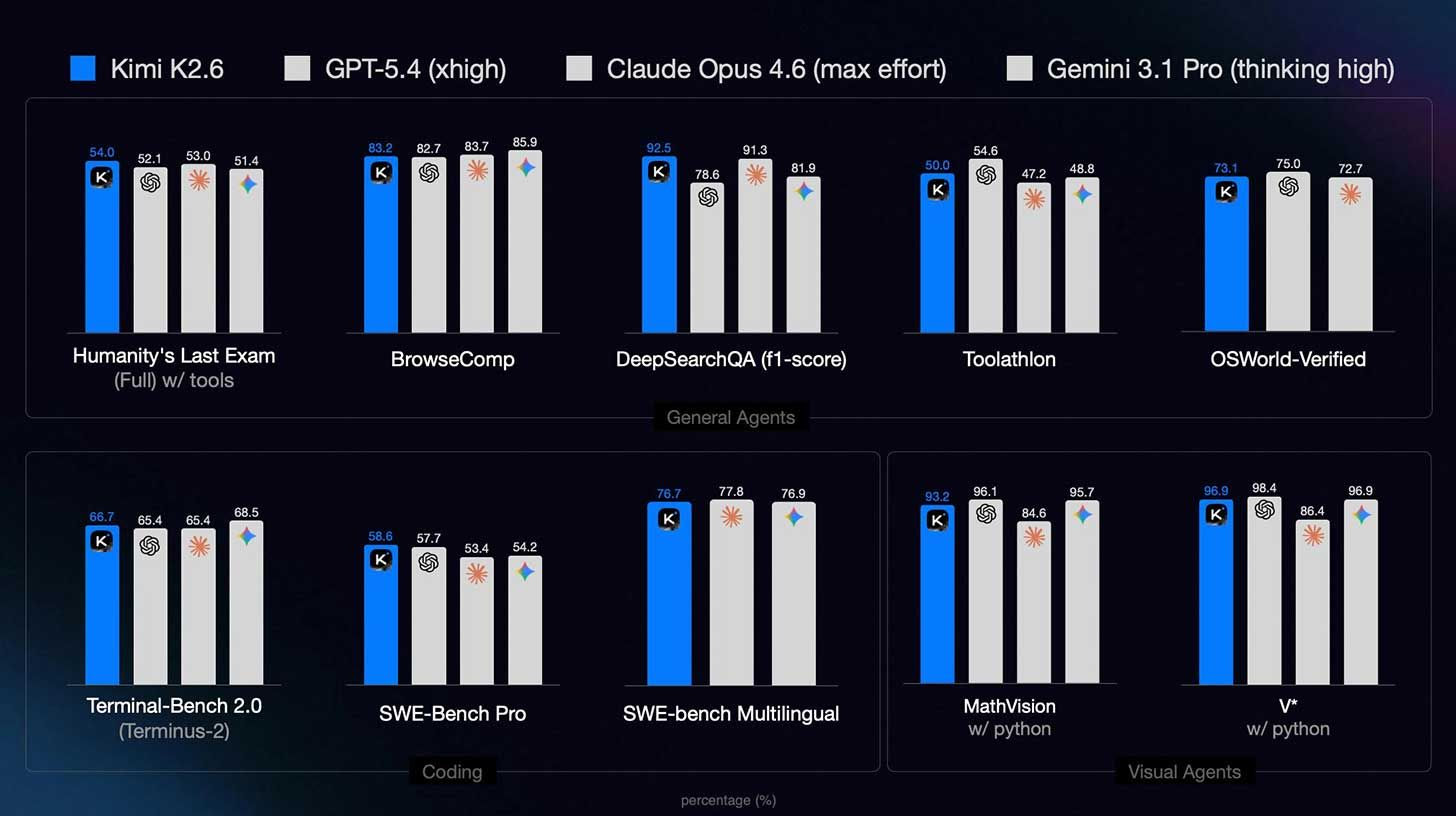
Today, Moonshot AI – the Chinese startup behind the popular Kimi assistant – open-sourced K2.6 , a new agentic coding model that, according to a comprehensive benchmark suite published by the company, either nears or outright outperforms the very frontier models Amodei cited. On Humanity’s Last Exam (HLE) with tools, a grueling reasoning benchmark designed to stump even the best models, K2.6 scores 54.0% – beating GPT-5.4 (52.1%), Opus 4.6 (53.0%), and Gemini 3.1 Pro (51.4%). On SWE-Bench Pro, the gold standard for real-world coding ability, K2.6 scores 58.6% , surpassing Opus 4.6 (53.4%) and Gemini 3.1 Pro (54.2%), while narrowly edging GPT-5.4 (57.7%).
The results are not a clean sweep – the Western models still lead on some benchmarks, particularly pure reasoning without tools – but the overall picture is unmistakable. A Chinese, open-source model is trading blows with the most advanced closed models from OpenAI, Anthropic, and Google. And in the categories that matter most for autonomous agents – long-horizon execution, tool use, and agent swarms – K2.6 is not just competitive. It is, in some dimensions, superior.
But the benchmarks, however impressive, are not the story. The story is what K2.6 does. The model can work continuously for 12+ hours across 4,000+ tool calls, refactoring an 8-year-old codebase or optimizing a niche-language inference engine from scratch. It can spin up 300 parallel sub-agents as a swarm – triple the capacity of its predecessor, K2.5. Always-on agents like OpenClaw and Hermes are already running on K2.6, with one internal Moonshot agent operating autonomously for five days straight, handling monitoring, incident response, and system operations without human intervention.
“This is not a model that answers questions,” said Dr. Elena Vasquez, an AI analyst who has tested K2.6 extensively. “This is a model that works. It takes a task and just … keeps going. For hours. For days. That is a fundamentally different capability than what most frontier models offer. They’re brilliant for 30 seconds. K2.6 is reliable for 30 hours.”
For developers frustrated by usage limits, rate throttling, and the unpredictable costs of closed APIs, K2.6 arrives as a powerful, cost-effective, and open alternative. And for the open-source community, it is a statement: the gap is closing. Faster than anyone predicted.
Part I: The Benchmark Sweep – By the Numbers
Moonshot AI has published an extraordinarily detailed benchmark suite for K2.6, comparing it against GPT-5.4 (with xhigh reasoning effort), Claude Opus 4.6 (max effort), and Gemini 3.1 Pro (high thinking level), as well as its own predecessor, K2.5. The results are spread across four categories: Agentic, Coding, Reasoning & Knowledge, and Vision.
Agentic Benchmarks (Tool Use & Autonomous Action)
This is where K2.6 shines brightest. On HLE-Full with tools – a version of Humanity's Last Exam that allows models to use search, code execution, and browsing – K2.6 scores 54.0%, beating every competitor. On DeepSearchQA (F1-score), K2.6 achieves 92.5%, far outpacing GPT-5.4 (78.6%) and Gemini 3.1 Pro (81.9%), while narrowly edging Opus 4.6 (91.3%). On accuracy, the gap is even wider: K2.6 at 83.0% vs. GPT-5.4 at 63.7%.
On Toolathlon, a benchmark for multi-step tool use, K2.6 scores 50.0%, ahead of Opus 4.6 (47.2%) and Gemini (48.8%), though behind GPT-5.4 (54.6%). On MCPMark, a test of Model Context Protocol integration, K2.6 ties Gemini (55.9%) and surpasses Opus (56.7%? Actually K2.6 matches Opus's 56.7? The table shows Opus 56.7*, K2.6 55.9 – a narrow gap).
Perhaps most significantly, on Claw Eval (pass^3) – a measure of reliable autonomous execution – K2.6 scores 62.3%, beating GPT-5.4 (60.3%) and Gemini (57.8%), though still behind Opus 4.6 (70.4%). But on the pass@3 metric (attempts three times), K2.6 is competitive at 80.9%.
Coding Benchmarks
On SWE-Bench Pro, K2.6 achieves 58.6%, surpassing Opus (53.4%), Gemini (54.2%), and GPT-5.4 (57.7%). On Terminal-Bench 2.0, a test of command-line and DevOps tasks, K2.6 scores 66.7%, ahead of GPT-5.4 (65.4%) and Opus (65.4%), though behind Gemini (68.5%). On SWE-Bench Multilingual, K2.6 scores 76.7%, effectively tied with Opus (77.8%) and Gemini (76.9%).
On LiveCodeBench (v6), a test of real-time coding, K2.6 reaches 89.6% – slightly ahead of Opus (88.8%) but behind Gemini (91.7%).
Reasoning & Knowledge (Without Tools)
Here, the Western models maintain a lead. On HLE-Full (no tools), K2.6 scores 34.7%, behind GPT-5.4 (39.8%), Opus (40.0%), and Gemini (44.4%). On GPQA-Diamond, a graduate-level reasoning test, K2.6 scores 90.5%, behind Gemini (94.3%) and GPT-5.4 (92.8%), but ahead of Opus (91.3%? Actually Opus 91.3, so K2.6 is slightly behind). On AIME 2026, a math competition, K2.6 scores 96.4%, competitive but behind GPT-5.4 (99.2%).
Vision Benchmarks
K2.6 is multimodal, and it performs respectably. On MMMU-Pro, it scores 79.4%, behind Gemini (83.0%) and GPT-5.4 (81.2%), but ahead of Opus (73.9%). With Python tool use, scores improve across the board, but the Western models maintain a slight edge.
“The pattern is clear,” said Vasquez. “When you give K2.6 tools – when you let it search, execute code, and iterate – it is world-class. When you force it to reason purely from its parameters, it is still good, but not quite at the frontier. That suggests Moonshot has optimized heavily for agentic capabilities. And that is exactly the right bet for the market.”
Part II: Long-Horizon Coding – 12 Hours, 4,000 Tool Calls
The benchmark numbers are impressive, but they do not capture what makes K2.6 truly different. For that, you have to look at the long-horizon demonstrations Moonshot has released.
In one internal test, K2.6 was tasked with downloading and deploying the Qwen3.5-0.8B model locally on a Mac – but with a twist: it had to implement and optimize the model inference in Zig, a niche systems programming language with very little example code or documentation.
K2.6 worked for 12 hours straight, making over 4,000 tool calls across 14 iterations. It researched Zig’s syntax, wrote inference code, ran benchmarks, identified bottlenecks, rewrote critical sections, and iterated again. By the end of the process, it had improved throughput from approximately 15 tokens per second to 193 tokens per second – a 1,200% improvement – ultimately achieving speeds 20% faster than LM Studio, a popular optimized inference tool.
“That is not code generation,” said Marcus Wei, an AI engineer who reviewed the test log. “That is software engineering. The model didn’t just write a function. It optimized a system. It learned a niche language. It benchmarked. It iterated. That is a level of autonomy I have not seen from any other model.”
In another test, K2.6 was asked to overhaul exchange-core, an 8-year-old open-source financial matching engine. The model analyzed CPU and allocation flame graphs, identified hidden bottlenecks, and reconfigured the core thread topology (from 4ME+2RE to 2ME+1RE) – a bold architectural change. Over 13 hours, it initiated over 1,000 tool calls and modified more than 4,000 lines of code. The result: a 185% leap in medium throughput (from 0.43 to 1.24 MT/s) and a 133% gain in peak performance (from 1.23 to 2.86 MT/s).
“What impressed me most was the surgical precision,” said a beta tester from Augment Code, quoted in Moonshot’s announcement. “When an initial path is blocked, K2.6 is strong at pivoting intelligently – following existing architectural patterns, finding hidden related changes, and keeping fixes scoped to the real problem.”
These long-horizon capabilities are not academic. They are directly applicable to the kind of autonomous agents that are increasingly being deployed in enterprise environments: agents that monitor systems, respond to incidents, refactor legacy codebases, and optimize performance – without human oversight.
Part III: Agent Swarms – Scaling Out, Not Just Up
One of K2.6’s most distinctive features is its agent swarm capability. Unlike traditional models that process tasks sequentially, K2.6 can dynamically decompose a complex task into heterogeneous subtasks and spin up parallel sub-agents to execute them simultaneously.
K2.6’s swarm architecture scales to 300 sub-agents executing across 4,000 coordinated steps simultaneously – triple the capacity of K2.5 (100 sub-agents, 1,500 steps). This parallelization dramatically reduces end-to-end latency for complex tasks.
In practice, this means K2.6 can:
Perform broad search and deep research simultaneously, combining complementary skills.
Analyze large-scale documents while generating long-form writing in parallel.
Generate multi-format content (documents, websites, slides, spreadsheets) in a single autonomous run.
The swarm can also turn any high-quality file – PDFs, spreadsheets, slides, Word documents – into Skills, capturing the document’s structural and stylistic DNA. Once a skill is created, K2.6 can reproduce the same quality and format in future tasks, creating a library of reusable workflows.
“The swarm capability is where K2.6 really separates from the pack,” said Dr. Alex Chen, an AI researcher focused on multi-agent systems. “Most models are single-threaded. They do one thing at a time. K2.6 can coordinate an army of sub-agents. That is not an incremental improvement. That is a different paradigm.”
Moonshot has also introduced Claw Groups, a research preview that extends the swarm architecture to heterogeneous agents running on different devices, different models, and different toolkits. A Claw Group can include agents running on local laptops, mobile devices, or cloud instances, each with its own specialized skills and memory contexts. K2.6 serves as the adaptive coordinator, dynamically matching tasks to agents based on skill profiles, detecting failures, and reassigning tasks as needed.
In an almost self-referential twist, Moonshot has been dogfooding Claw Groups to run its own agent marketing team – specialized agents like Demo Makers, Benchmark Makers, Social Media Agents, and Video Makers working together to produce launch campaigns.
“We’re moving beyond simply asking AI a question or assigning AI a task,” the company writes. “We’re entering a phase where human and AI collaborate as genuine partners – combining strengths to solve problems collectively.”
Part IV: Proactive Agents – Five Days of Autonomy
The ultimate expression of K2.6’s capabilities is the proactive agent – an AI that runs continuously, managing tasks without being prompted. Moonshot’s internal RL infrastructure team used a K2.6-backed agent that operated autonomously for five days straight, handling:
Monitoring: Watching system metrics and logs.
Incident response: Detecting anomalies and taking corrective action.
System operations: Managing ongoing tasks and workflows.
The agent’s worklog, anonymized and shared by Moonshot, shows a persistent context spanning days, multi-threaded task handling, and full-cycle execution from alert to resolution. This is not a chatbot that answers when called. It is a digital employee that never sleeps.
Always-on agents like OpenClaw and Hermes – open-source projects for autonomous computer use – are already running on K2.6. According to early testers, the model delivers “more precise API interpretation, stabler long-running performance, and enhanced safety awareness during extended research tasks.”
Moonshot has quantified these gains with an internal Claw Bench evaluation suite, covering five domains: Coding Tasks, IM Ecosystem Integration, Information Research & Analysis, Scheduled Task Management, and Memory Utilization. Across all metrics, K2.6 significantly outperforms K2.5 in task completion rates and tool invocation accuracy – particularly in workflows requiring sustained autonomous operation without human oversight.
“For a no-code environment, AI has to handle every edge case,” said a tester from a low-code platform. “There’s no developer to step in when something doesn’t work as expected. K2.6 is noticeably more effective than K2.5 at navigating nuanced API behaviors and recovering when things break. It runs longer-horizon tasks before hitting a wall.”
Part V: The Open-Source Advantage – Cost, Control, and Customization
K2.6 is open-source – available via Kimi.com, the Kimi App, the API, and Kimi Code. The model weights are publicly accessible, and Moonshot has published detailed instructions for self-hosting.
The implications are significant. For developers frustrated by the usage limits, rate throttling, and unpredictable costs of closed APIs (OpenAI’s GPT-5.4 is expensive; Anthropic’s Opus 4.6 is even more so), K2.6 offers a powerful alternative. The cost per inference is a fraction of the closed models – Moonshot has not published exact pricing, but early estimates suggest K2.6 is 5-10x cheaper than GPT-5.4 for comparable performance.
“Given frustrations over usage rates and the rise of autonomous agents, K2.6 looks like a powerful, cost-effective new option for agentic workflows,” said Sarah Jenkins, an AI infrastructure strategist. “If you’re building an agent that makes thousands of tool calls per day, the cost difference between closed APIs and an open-source, self-hosted model is the difference between viable and impossible.”
The open-source nature also enables customization. Developers can fine-tune K2.6 for their specific domains, integrate it with internal tooling, and deploy it on their own infrastructure – with no data leaving their control. For enterprises with strict data residency or security requirements, this is non-negotiable.
“Closed models are great for prototyping,” said Chen. “But for production agents that handle sensitive data or run at scale, you need control. K2.6 gives you that control without sacrificing capability. That is a game-changer.”
Part VI: The China Factor – And the Amodei Prediction
Moonshot AI is a Chinese company. K2.6 was developed in Beijing, by a team that, until recently, was largely unknown outside of Asia. The model’s performance – particularly on agentic and coding tasks – is a direct challenge to the narrative that Chinese AI labs are irreversibly behind their Western counterparts.
Amodei’s “6 to 12 months” prediction, made just two weeks ago, now looks premature at best. On some benchmarks, K2.6 is not 6 months behind. It is ahead. On others, the gap is narrow enough that a single training run could flip the leaderboard.
“The open-source community has been saying for years that the gap is closing,” said Vasquez. “But this is the first time we have a model that is demonstrably competitive across the board – and open-source, and from China. That’s three disruptions in one.”
Of course, the geopolitical context cannot be ignored. K2.6’s release comes amid ongoing US export controls on advanced semiconductors to China. Moonshot AI has not disclosed what hardware was used to train K2.6, but the model’s existence – and its performance – suggests that Chinese labs have found ways to work around the restrictions, or that the restrictions are less effective than intended.
“The US thought that cutting off access to NVIDIA’s most advanced chips would slow Chinese AI development,” said Wei. “K2.6 is evidence that it didn’t. Not enough. The gap is closing. And it’s closing faster than anyone in Washington wants to admit.”
Conclusion: A New Baseline for Open Agentic AI
Kimi K2.6 is not the final word in open-source coding models. It is, however, a new baseline. For the first time, developers have access to a model that can reason, code, use tools, coordinate swarms, and run autonomously for days – at a fraction of the cost of closed alternatives, with full control over deployment and customization.
The benchmark wars will continue. GPT-5.5, Opus 4.7, and Gemini 3.2 are surely in development. But K2.6 has shifted the terms of debate. The question is no longer “can open-source models compete?” The question is “how long until open-source models lead?”
For Dario Amodei, the prediction of a 6-12 month gap was a statement of confidence. For Moonshot AI, it was a challenge. And with K2.6, they have answered.
The long-horizon agentic future is open-source. And it just arrived.
Your one-stop shop for automation insights and news on artificial intelligence is EngineAi.
Did you like this article? Check out more of our knowledgeable resources:
Watch this space for weekly updates on digital transformation, process automation, and machine learning. Let us assist you in bringing the future into your company right now